Get your Apple Watch data using CWCloud FaaS engine

This blog post will help us illustrate a concrete use case for using CWCloud's FaaS1 engine — both to expose serverless functions as public webhooks, and to show how to interact with LLMs2.
Besides IT, I enjoy doing sports regularly, especially running and powerlifting. For some time now, I’ve been using an Apple Watch SE to collect metrics and track my progress, especially in terms of endurance and cardio.
For a "non-tech" user, the level of detail and data presentation during an exercise is very satisfying. Here's, for example, a breakdown of what happens during a run: GPS positions, heart rate, and zones throughout the workout...
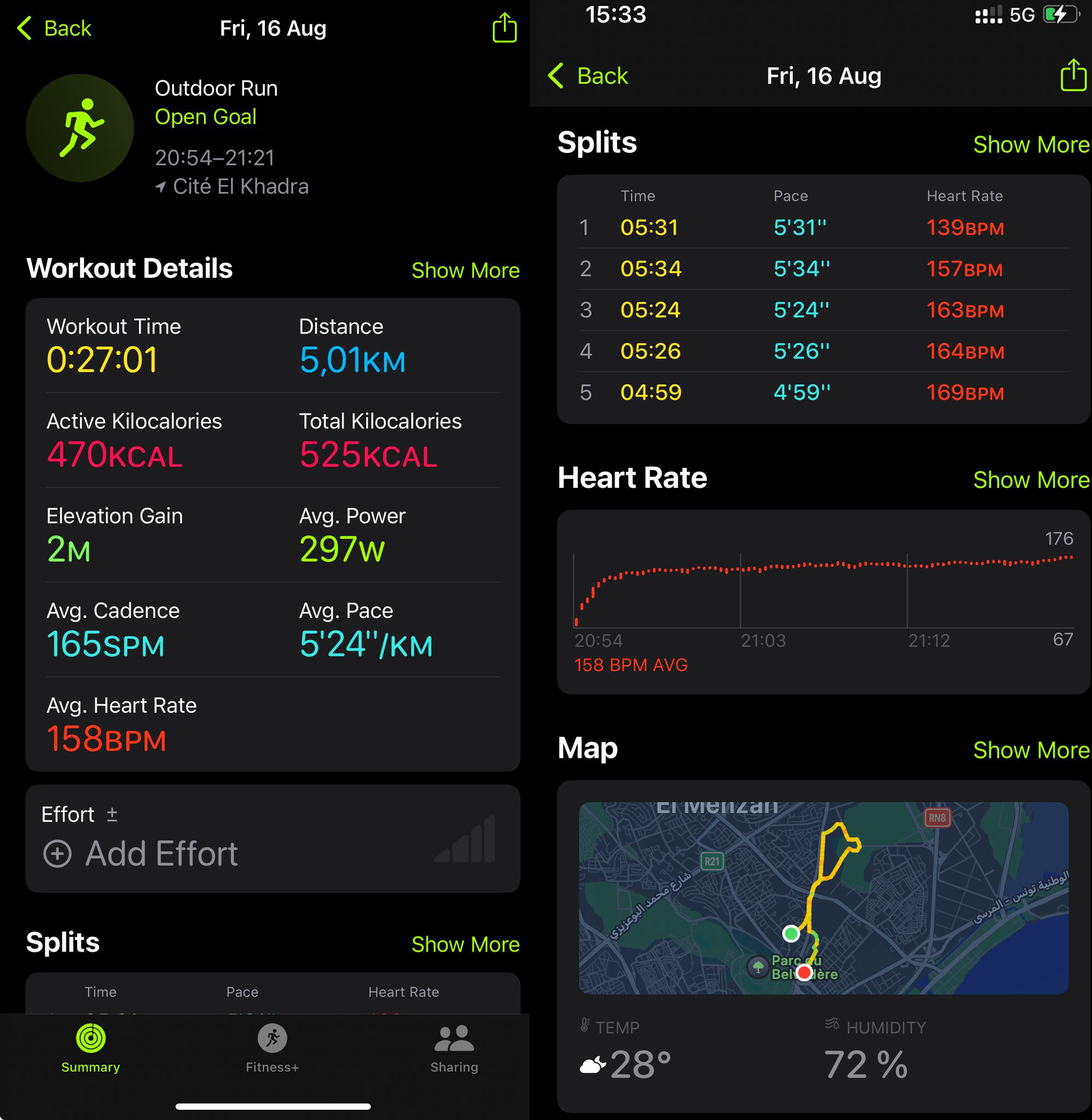
The watch also provides tons of other data on sleep quality, resting heart rate, calories burned... but there’s always been one thing that frustrates me compared to other models I’ve used in the past, like Fitbit watches: no webservice nor API for developers. And yet, I’d really like to fetch those data in order to process it with LLMs using the CWCloud low-code FaaS engine.
However, no online API doesn’t necessarily mean it’s impossible to retrieve the data: we can see that many apps on the iPhone still manage to access the watch’s data, like Strava, MyFitnessPal...
Most of the time, these apps access data directly from the iPhone using Apple’s HealthKit framework and by requesting the proper permissions in Apple’s security settings.
Still, it requires quite a bit of effort for someone who’s not an iOS mobile developer to build and validate a Swift app just to send data to a webhook. So I looked to see if someone had already done that job — and someone had, with the Health Auto Export app.
The app has pretty bad reviews, but once you read the comments, it’s clear why: people didn’t understand what it’s for. It’s not about creating pretty statistical dashboards, but about exporting Apple health data in developer-friendly formats (CSV or JSON), and scheduling those exports to external connectors (REST/HTTP webhooks, MQTT files, Dropbox...).
In our case, that’s exactly what we needed. Here’s how to configure an HTTP webhook, for instance, to send the data to CWCloud in an automation that runs every minute:

Every minute, the CWCloud serverless function receives a JSON payload in the following format:
{
"data" : {
"metrics" : [
{
"units" : "count\/min",
"data" : [
{
"Min" : 79,
"date" : "2025-06-30 23:17:40 +0200",
"Avg" : 79,
"Max" : 79,
"source" : "Idriss’s Apple Watch"
},
{
"Min" : 66,
"Max" : 66,
"Avg" : 66,
"source" : "Idriss’s Apple Watch",
"date" : "2025-06-30 23:23:45 +0200"
},
{
"Max" : 66,
"date" : "2025-06-30 23:26:52 +0200",
"source" : "Idriss’s Apple Watch",
"Min" : 66,
"Avg" : 66
}
],
"name" : "heart_rate"
}
]
}
}
In the automation, you'll notice I filtered only the heart_rate metric, because otherwise it would send many others — not just from the Apple Watch, but also from apps like MyFitnessPal, which tracks your macros (kcal, proteins, fats, carbs, calcium, etc.) from your diet. So there’s a lot of room for very interesting usecases here 😁.
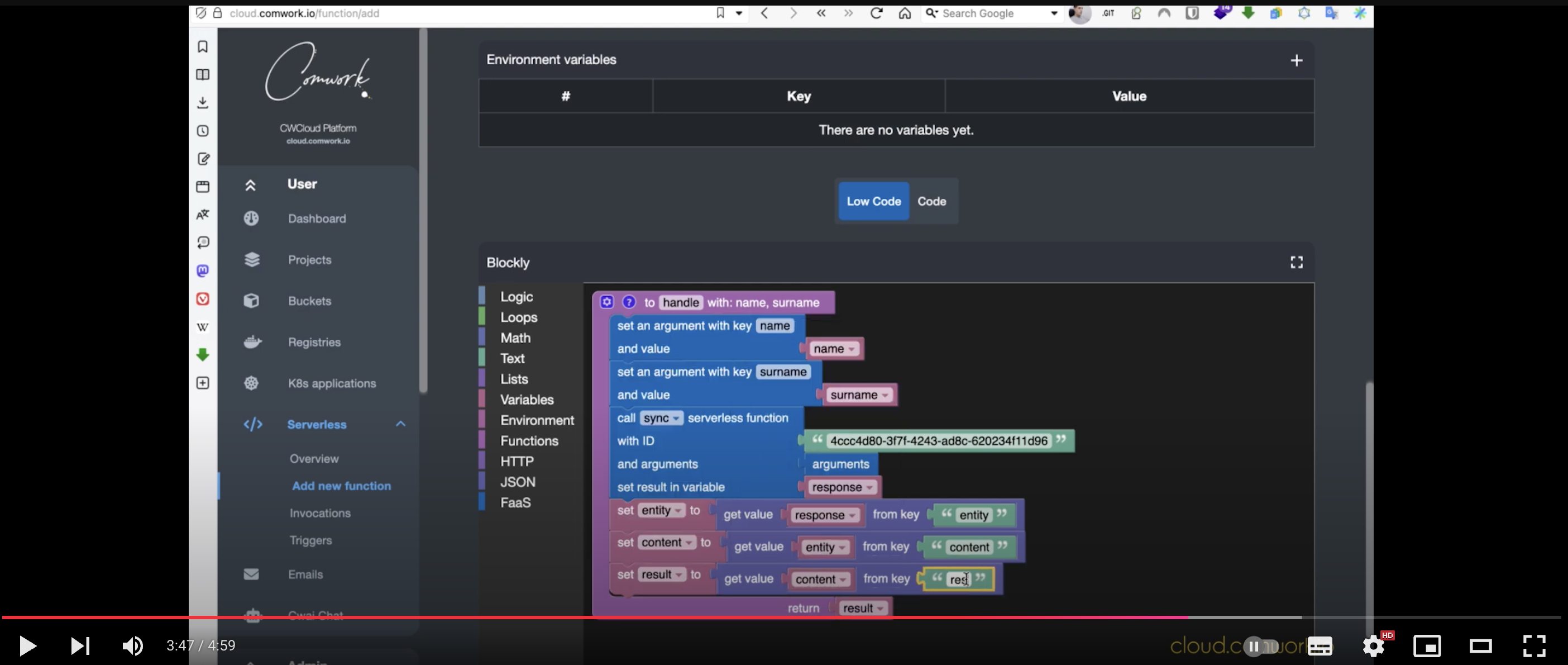
That been said, this payload isn’t compatible with the interface contract of our serverless engine with the standard endpoints we’ve documented in several demos, where we expect function parameters in advance.
However, there is an endpoint /v1/faas/webhook/{function_id} (or /v1/faas/webhook/{function_id}/sync if you want to receive the function’s response directly in the HTTP response). In this case, your function just needs to be defined with a single raw_data argument like this:
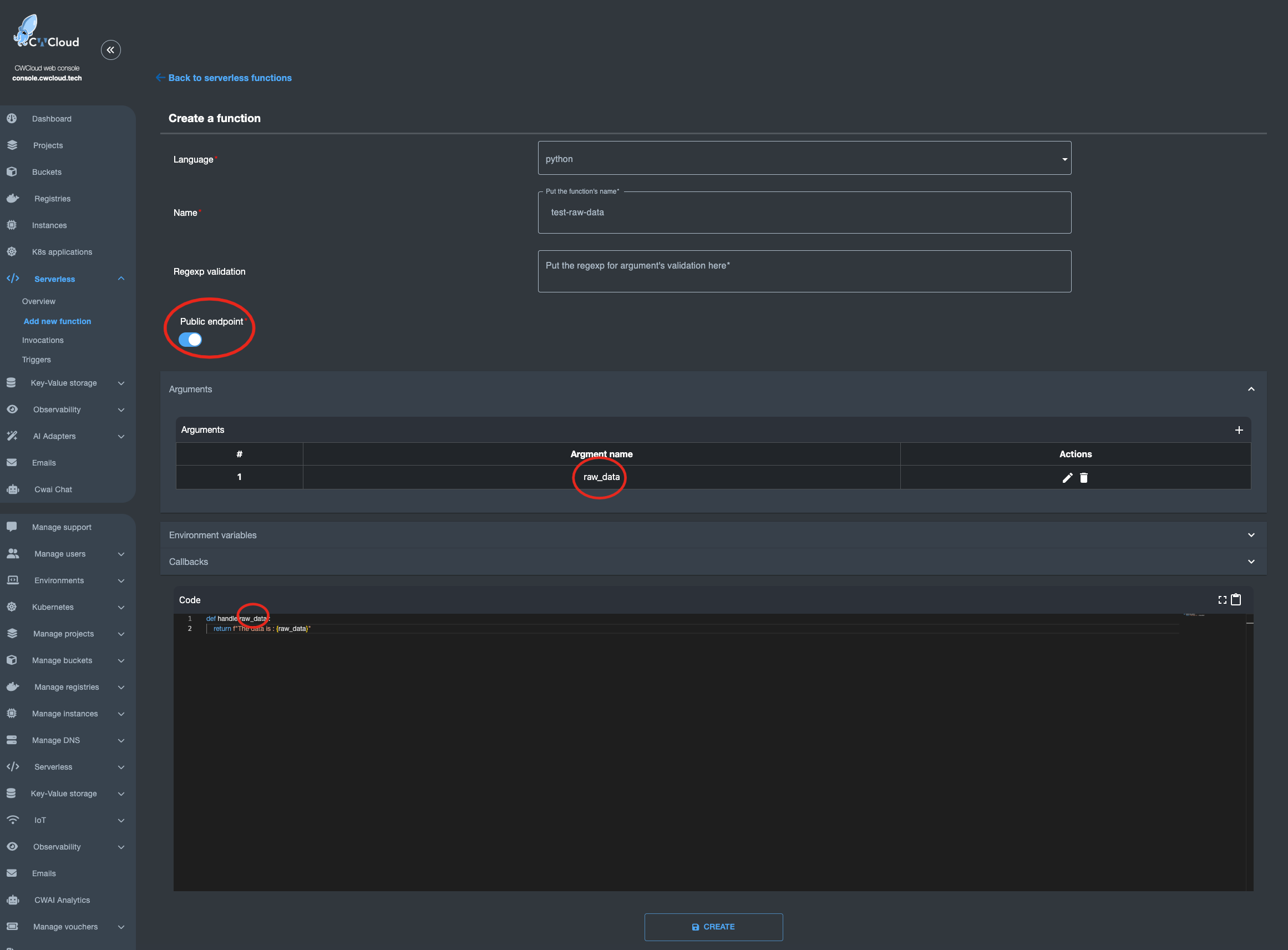
Once that’s done, it becomes very easy to invoke the function by passing whatever body you want — which you can then parse directly in your code:
$ curl "https://api.cwcloud.tech/v1/faas/webhook/ecb10330-02bf-400b-b6a8-d98107324ac3/sync" -X POST -d '{"foo":"bar"}' 2>/dev/null | jq .
{
"status": "ok",
"code": 200,
"entity": {
"id": "78774026-f75e-4c7c-850a-9b9eb2cb2ec0",
"invoker_id": 3,
"updated_at": "2025-07-05T14:39:53.119780",
"content": {
"args": [
{
"key": "raw_data",
"value": "{\"foo\":\"bar\"}"
}
],
"state": "complete",
"result": "The data is : {\"foo\":\"bar\"}\n",
"user_id": null,
"function_id": "ecb10330-02bf-400b-b6a8-d98107324ac3"
},
"created_at": "2025-07-05T14:39:52.443918"
}
}
As you’ve probably guessed, in the Health Auto Export app automation, it’s a URL like https://api.cwcloud.tech/v1/faas/webhook/{function_id} that you’ll need to define (no need for /sync at the end since you don’t care about waiting for the result).
Note: We also exposed the function as public so it could be called without authentication, but that’s not necessarily what you want. Don’t forget that you’re billed per token consumed — for example, if you use public LLMs — so you probably don’t want just anyone calling your webhook. You can totally keep the function private and add an X-User-Token header in the Health Auto Export app automation.
Now that we know how to create a webhook, here’s the Blockly3 code to extract the average heart rate, send it to the gpt4omini LLM. In this case, we asked the LLM to react with an emoji based on the value it receives, and send the result to Discord:
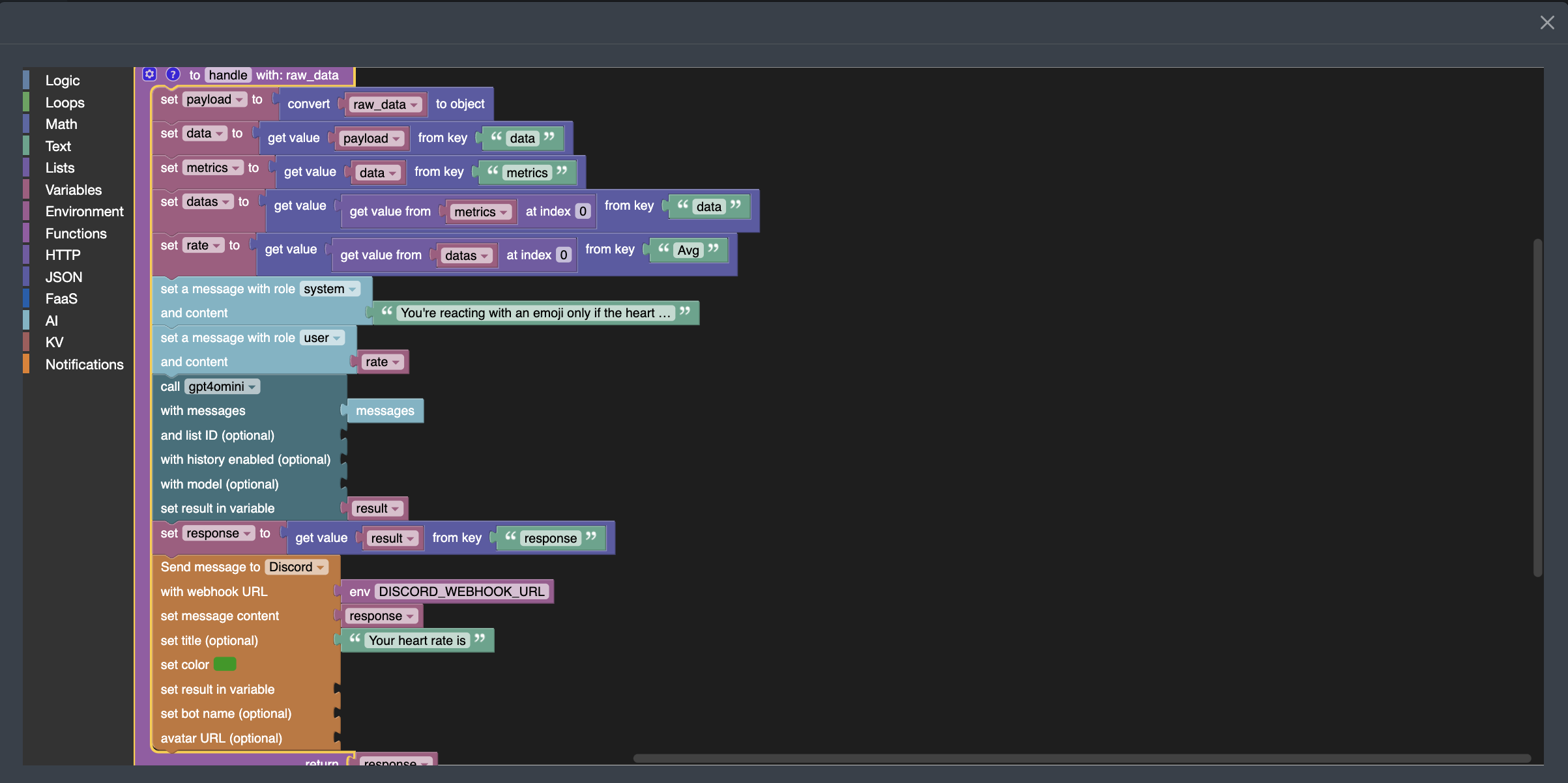
You can see that I'm passing the following sentence "You're reacting with an emoji only if the heart rate is too slow or to high" as a system prompt and the fetched heart rate metric as a user prompt.
Moreover, you should know that AI blocks require authentication to invoke the CWCloud AI API. If you want to keep this webhook open to anyone, you’ll need to create an API key following this tutorial, and inject it into an environment variable called AUTH_HEADER_VALUE like this:
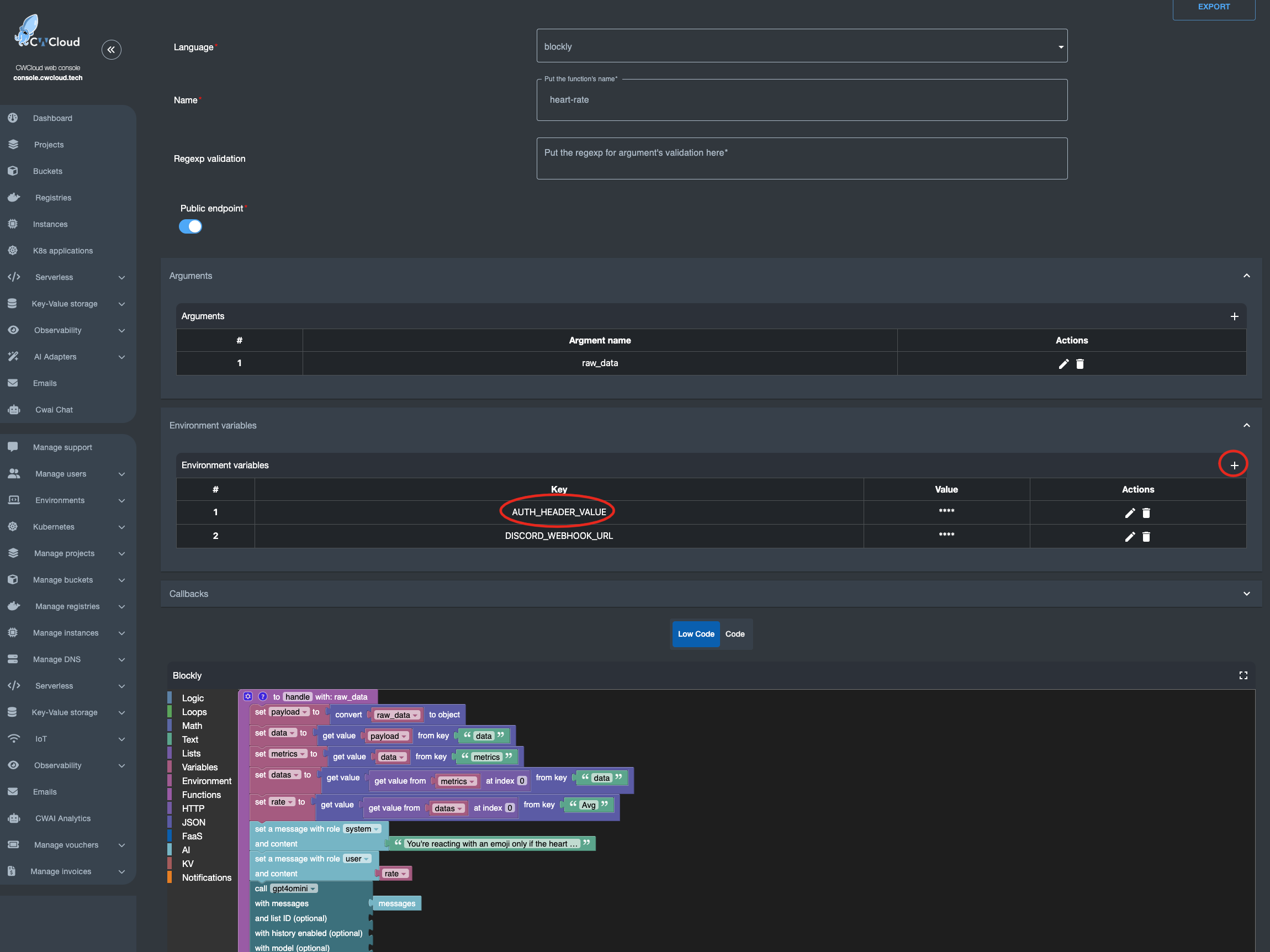
In this case, anyone is able to invoke your webhook and your account will be billed for usage in the case you’re using public AI models. You can also choose to use your own LLM hosted on your own infrastructure instead — in which case it makes more sense to keep the webhook public 😇.
Also note: if the AUTH_HEADER_VALUE variable is set, it takes priority over user authentication when calling the webhook with an authenticated request.
You can also see in the screenshot above that a Discord webhook was defined in another environment variable DISCORD_WEBHOOK_URL so it can be used to send the LLM’s response into Discord. Here’s the result:
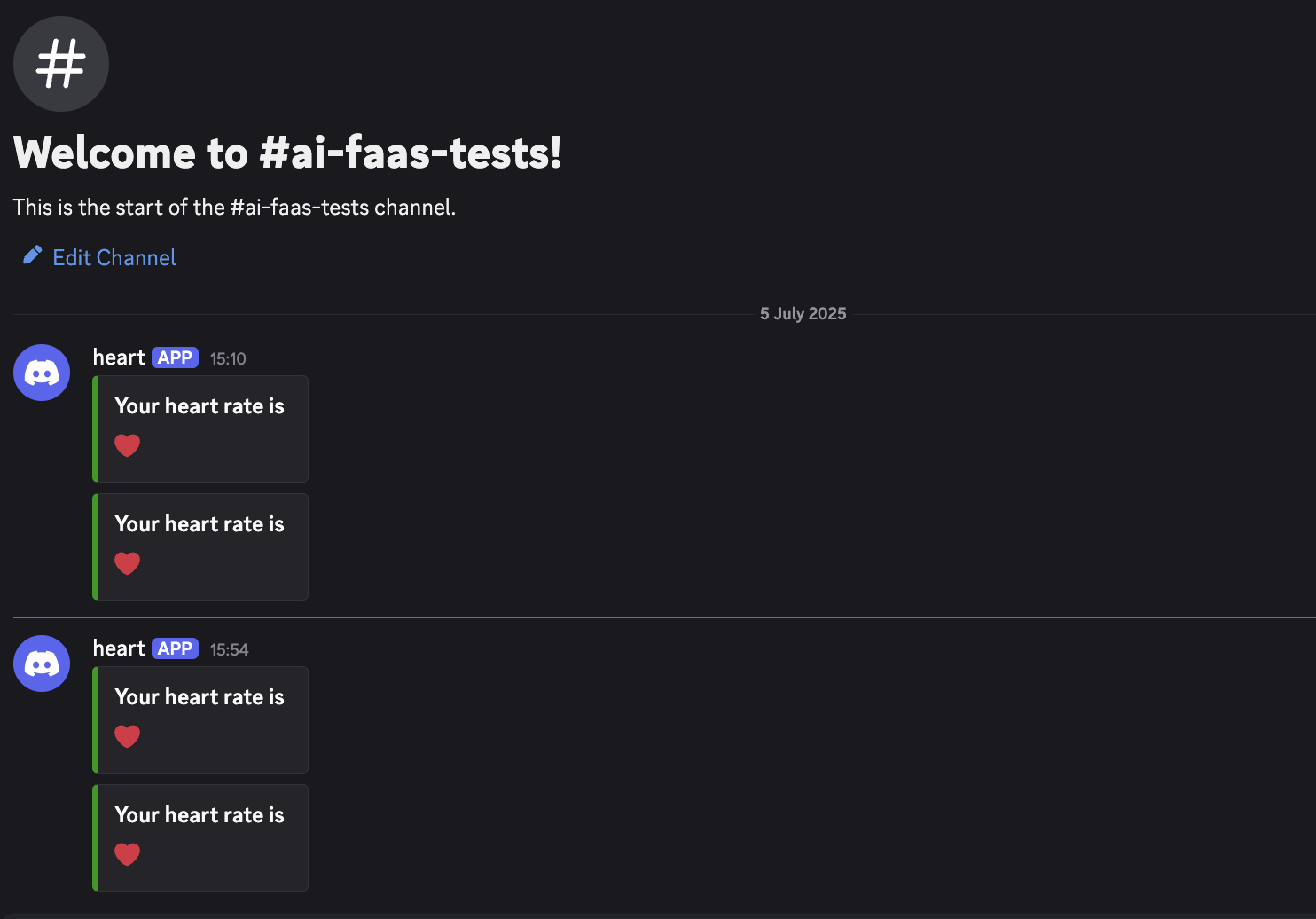
We can see that so far, everything’s going just fine with my heart 😅